16-bit Alpha Blending Using an 8-bit Mask
|
Information in this document is provided in
connection with Intel products. No license, express or
implied, by estoppel or otherwise, to any intellectual
property rights is granted by this document. Except as
provided in Intel's Terms and Conditions of Sale for such
products, Intel assumes no liability whatsoever, and
Intel disclaims any express or implied warranty, relating
to sale and/or use of Intel products including liability
or warranties relating to fitness for a particular
purpose, merchantability, or infringement of any patent,
copyright or other intellectual property right. Intel
products are not intended for use in medical, life
saving, or life sustaining applications. Intel may make
changes to specifications and product descriptions at any
time, without notice. Copyright (c)
Intel Corporation 1997.
*Third-party brands and names are the
property of their respective owners.
|
This application note will cover the optimization techniques
used to implement 16-bit alpha blending with a predefined 8-bit
mask using MMXTM Technology for Microsoft* DirectDraw.
16-bit alpha blending using 8-bit masks is normally used in image
manipulation and anti-aliasing sprites for games. The 16-bit
alpha blending routine uses MMX Technology to calculate the alpha
blending result for four pixels (per iteration) using 16-bit
source, 16-bit destination, and 8-bit alpha bitmaps. This appnote
will provide an overview of the alpha blending equation,
implementation/optimization techniques for 16-bit RGB alpha
blending on a Pentium II(R) Processor, performance results, and
functions for 565 and 555 color space alpha blending. The
functions provided in this appnote are optimized to work with
DirectDraw surfaces in system memory on Pentium II Processors.
For a general coverage of alpha blending using MMX Technology
please refer to the appnote Using MMX
TM Instructions to Implement Alpha Blending.
The technique for alpha blending uses the simple
mathmatical function:
Co=Cs*(A)+(1-A)*Cd
Figure 1: Floating Point Alpha Blend Equation
Where the values for C are either the red, green,
or blue component of a pixel in the source and destination image.
The subscript s denotes the source color and d
denotes the destination color. In this equation the source pixels
are multiplied by an alpha factor A while the destination pixels
are multiplied by the inverse alpha value (1-A). The range for
the alpha value in A is between zero and one. Each color
component (R,G,B) must have the same dynamic range for the source
and destination bitmap (i.e. five bits for red in source and
destination). However dynamic ranges between color components
(i.e. Red is five bits and Green is six bits) within a pixel need
not be the same.
This section describes the various aspects of writing the
16-bit alpha blending routine shown in the Appendix. These factors consist of the
make up of function inputs, video hardware, pixel data storage
and arrangement, Pentium II Processor cache and instruction
execution, integer alpha blending calculations, MMX Technology
implementation, work reduction, and video surfaces.
The inputs for both alpha blending routines consist of the
memory location, pitch for a row of pixels, and coordinates for
the alpha, source, and destination bitmaps (shown in Figure 2).
These attributes can be obtained from the DirectDraw data
structure DDSURFACEDESC after a call to lock the DirectDraw
surface. For the function to work properly the alpha mask must
have a one to one mapping with the source surface. The alpha
blending is bounded by iDstW(width) and iDstH(height) which limit
the operation to a rectangular area for the alpha mask, source
bitmap, and destination bitmap.
| |
void ablend_555(unsigned char
*lpAlpha,unsigned int iAlpPitch,
unsigned char *lpSrc,unsigned int iSrcX, unsigned int
iSrcY,
unsigned int iSrcPitch, unsigned char *lpDst,
unsigned int iDstX, unsigned int iDstY,
unsigned int iDstW, unsigned int iDstH,
unsigned int iDstPitch)
|
|
Figure 2: 555 Alpha Blending Function Prototype
The make up of the video hardware affects the display of the
resulting alpha blended image. The image must conform to the bit
allocations for the video hardware so that the surface is
displayed properly. There are two methods to represent 16-bit
color in video hardware. Both methods 555 and 565 describe bit
allocations for the RGB color components that make up a pixel. In
the case of 555, each color component is allocated five bits with
the most significant bit left unused. For 565 the extra bit is
use in the green component. The arrangement of color components
(either RGB or BRG) is dependent on the implementation of the
video hardware.
In DirectDraw applications, the pixel format is video card
dependent and stored sequentially in RGB format. This applies to
the source and destination bitmaps which use 16-bit RGB color.
The alpha mask is stored in memory in eight bit format
independent of the video hardware. Knowledge of bitmap and mask
storage is useful when attempting to access the pixels for alpha
blending via surface pointers. In DirectDraw, surfaces are
allocated on four byte boundaries for each row of pixels. A
surface that does not fit in the four byte boundaries is padded
with extra bytes. For example a DirectDraw surface with
dimensions of 23 pixels wide, 23 pixels high, and 16-bit depth,
will create a span of 46 bytes per row (23 pixels*2 bytes).
However when DirectDraw allocates the memory it will create a
surface with a pitch of 48 bytes per row to maintain four byte
alignement. Thus the width of some bitmaps will not correspond to
the amount of actual system or video memory used by a row of
pixels. The padding will skew the pixel accesses for each
successive line. To correct the problem pitch is used to advance
the surface pointer to the next line of the image.
The two significant features of the Pentium II Processor
affecting the implementation of the alpha blending algorithm, are
non-aligned cache line access, and dynamic instruction execution.
A non-aligned cache line access occurs when an application
accesses data on a cache line that is not four byte aligned. For
example, when an application accesses a single byte at the
beginning of a cache line and then proceeds to access a word or
dword, a non-aligned access occurs. On a Pentium Processor with
MMX Technology this non-aligned cache line access causes a one
cycle penalty each time the data is read from the cache. The
Pentium II Processor allows non-aligned cache line accesses
without a penalty. Therefore pre and post alignment of data
accesses is no longer necessary. The Pentium II Processor also
utilizes dynamic execution with instruction look ahead to
determine instructions for execution in its five execution units
thus doing away with the need for pairing optimizations. Assembly
instructions written for the Pentium II Processor will no longer
require pre/post data alignment code and pairing optimizations in
MMX Technology code.
The equation for alpha blending discussed in Section 2.1
showed that the alpha value was a floating point number between
zero and one. However the data for the alpha mask, as well as the
source and destination bitmaps are represented in integer format.
Since the conversion of each value to floating point for the
equation would cost too many cycles, the alpha blending algorithm
utilizes an integer scaling factor to calculate color components
in integer format. An indepth discussion of integer scaling is
described in the November 1995 issue of IEEE Computer Graphics
and Applications article ,"Three Wrongs Make a Right"
by James F. Blinn. By applying the integer scaling method
described in the article, the 555 alpha blending algorithm is
reduced to the simple series of shifts and multiplies shown in
Figure 3. The alpha value A, which is in eight bits, is scaled by
shifting right three bits to a five bit integer.
C1= Cs*(A)+(31-A)*Cd
Co=(C1+16)+((C1+16)>>5)>>5
Figure 3: 5-Bit Integer Alpha Blend Equation
In the case of 565 alpha blending, the green
component utilizes the six bit integer alpha blending equation
shown in Figure 4. The alpha value A is scaled to a six bit
integer by shifting right by two bits.
C1= Cs*(A)+(63-A)*Cd
Co=(C1+32)+((C1+32)>>6)>>6
Figure 4: 6-Bit Integer Alpha Blend Equation
There are two optimizations that improve the performance of
the alpha blending by reducing the amount of instructions to be
executed. In the first method early out testing, the algorithm
takes into account the fact that the alpha blending equation will
display destination pixels when the alpha mask is zero and source
pixels when the alpha mask is a five or six bit run of ones. By
using a simple two dword comparison for a run of zeros and ones
the alpha blending equation can be skipped. This method works
well for long runs of ones or zeros in the alpha mask (such as a
large control panel that is alpha blended against a background
image). The second method, pre-processing alpha masks, require
that each alpha mask be reduced to the dynamic range of each
color component. For 555 alpha blend routine the alpha mask can
be preprocessed to a five bit mask value to avoid the in function
shift. For the 565 alpha blend algorithm two preproccessed masks
are required -- one for five bits (for red and blue calculations)
and six bits (for green calculations). This technique was not
used in the alpha blending functions below because it is easier
to generate an eight bit alpha mask for use in both 565 and 555
alpha blending routines.
The functions provided in the Appendix
will operate on surfaces allocated in system or video memory.
However when applied to video surfaces (either as a source,
destination or both) there will be a significant performance
degradation. The degradation occurs when video memory is accessed
by the PCI bus from a PCI video card. Every request for a pixel
in video memory is passed through the PCI bus which is
significantly slower than the memory bus. This is also compounded
by non-cacheable video memory so that every time the pixel is
reused (such as the case for isolating the RGB components of the
pixel in the algorithm below) a request is places on the PCI bus
for the pixel information. There are two solutions for resolving
the performance bottleneck. The first solution is to apply alpha
blending to surfaces allocated in system memory and then copy the
completed image into video memory. Thus the PCI bus is only used
for large block transfers to video memory. If the surfaces must
remain in video memory then all requests for pixel information on
video surfaces should be cached. For example, the first request
for a pixel from a video surface should read multiple bytes into
a temporary storage location in system memory, while subsequent
access to the video surface is directed to the cache area.
The MMX Technology implementation takes advantage of work
reduction and integer calculations to create resulting alpha
blended pixel map. The SIMD instructions read in four values from
the alpha stream to determine if the four runs of pixels require
alpha blending. For pixel runs that require alpha blending the
integer equation is applied to the source and destination pixel
streams. The MMX Technology data flow is shown in Figure 5 for
the green component implementation in the five bit alpha blending
algorithm. This is an exact replication of the integer equation
shown in Figure 3.

Figure 5: MMX Technology Data Flow for Green Component Alpha
Blend
The following test results were obtained from a prototype
233MHz Pentium II using system memory blocks ranging from 2k to
64k in size. Both source and destination surfaces were allocated
the same sized memory blocks. The source was zero filled and the
destination was filled by the maximum pixel value (0x7FFF for 555
pixels and 0xFFFF for 565 pixels). The eight bit alpha values
used in the calculations were randomly generated. The two
routines, 565 and 555 alpha blending, generated very similar test
results. Therefore the results of both routines were approximated
to generate a combined MMX Technology result versus scalar
assembly performance shown in Figure 6. The performance of the
MMX Technology routines were between four to five times faster
than the scalar assembly routine. For small pixel runs the
benefits of MMX Technology is minor compared to scalar assembly
because of the data setup overhead for alpha blend values and
pixel component manipulation. With larger runs of pixels the
benefits of work reduction and SIMD shows in the cases of 8K to
64K block which translate to sixteen bit pixel blocks of 64x64 to
256x128.
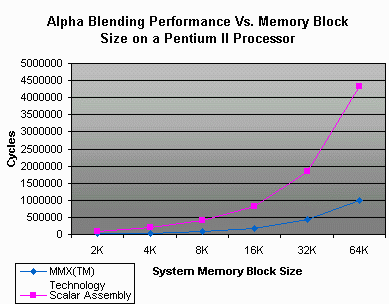
Figure 6: Alpha Blending Vs. Memory Block Size on a Pentium II
Processor
16-bit alpha blending routine with an 8-bit mask produces a
performance boost on the Pentium II processor when the
optimizations discussed in Section 2.2
are implemented. This was shown in Section 3.0, where the
performance boost was between four to five times faster than the
equivalent assembly routine. MMXTM Technology was the
primary contributor to the speed increase by processing four
pixels per loop iteration. However the Pentium II Processor eased
code implementation by dispensing the need for pairing
instructions (by using dynamic execution) and aligned cache line
accesses for surfaces in system memory. The combinatory effect is
an algorithm that is significantly faster than its scalar
assembly counterpart.
/*Alpha blending routine for 555 video hardware
lpAlpha=Pointer to location of 8-bit alpha mask
iAlpPitch=The span of a row in the alpha mask
lpSrc=Pointer to location of 16-bit 555 source bitmap
iSrcX=Starting X location of 16-bit source bitmap
iSrcY=Starting Y location of 16-bit source bitmap
iSrcPitch=The span of a row of pixels in the Source bitmap
lpDst=Pointer to location of 16-bit 555 destination bitmap
iDstX=Starting X location of 16-bit destination bitmap
iDstY=Starting Y location of 16-bit destination bitmap
iDstW=Width in pixels for alpha mask, source and destination bitmaps
iDstH=Height in pixels for alpha mask, source and destination bitmaps
iDstPitch=The span of a row of pixels in the destination bitmap*/
void ablend_555(unsigned char *lpAlpha,unsigned int iAlpPitch,
unsigned char *lpSrc,unsigned int iSrcX, unsigned int iSrcY,
unsigned int iSrcPitch, unsigned char *lpDst,
unsigned int iDstX, unsigned int iDstY,
unsigned int iDstW, unsigned int iDstH,
unsigned int iDstPitch)
{
//Mask for isolating the red,green, and blue components
static __int64 MASKR=0x001F001F001F001F;
static __int64 MASKG=0x03E003E003E003E0;
static __int64 MASKB=0x7C007C007C007C00;
//constants used by the integer alpha blending equation
static __int64 SIXTEEN=0x0010001000100010;
static __int64 FIVETWELVE=0x0200020002000200;
pointer for linear destination
unsigned char *lpLinearDstBp=(iDstX<<1)+(iDstY*iDstPitch)+lpDst; //base for linear source
pointer unsigned char *lpLinearSrcBp=(iSrcX<<1)+(iSrcY*iSrcPitch)+lpSrc; //base linear alpha
for unsigned char *lpLinearAlpBp=iSrcX+(iSrcY*iAlpPitch)+lpAlpha; //base pointer
_asm{
mov esi,lpLinearSrcBp; //src
mov edi,lpLinearDstBp; //dst
mov eax,lpLinearAlpBp; //alpha
mov ecx,iDstH; //ecx=number of lines to copy
mov ebx,iDstW; //ebx=span width to copy
test esi,6; //check if source address is qword aligned
//since addr coming in is always word aligned(16bit)
jnz done; //if not qword aligned we don't do anything
primeloop:
movd mm1,[eax]; //mm1=00 00 00 00 a3 a2 a1 a0
pxor mm2,mm2; //mm2=2;
movq mm4,[esi]; //g1: mm4=src3 src2 src1 src0
punpcklbw mm1,mm2; //mm1=00a3 00a2 00a1 00a0
loopqword:
mov edx,[eax];
test ebx,0xFFFFFFFC; //check if only 3 pixels left
jz checkback; //3 or less pixels left
//early out tests
cmp edx,0xffffffff; //test for alpha value of 1
je copyback; //if 1's copy the source pixels to the destination
test edx,0xffffffff; //test for alpha value of 0
jz leavefront; //if so go to the next 4 pixels
//the alpha blend starts
//i=a*sr+(31-a)*dr;
//i=(i+16)+((i+16)>>5)>>5;
movq mm5,[edi]; //g2: mm5=dst3 dst2 dst1 dst0
psrlw mm1,3; //mm1=a?>>3 nuke out lower 3 bits
movq mm7,MASKG; //g3: mm7=green mask
movq mm0,mm1; //mm0=00a3 00a2 00a1 00a0
movq mm2,MASKR; //g4: mm2=31
pand mm4,mm7; //g5: mm4=sg3 sg2 sg1 sg0
psubsb mm2,mm0; //g6: mm2=31-a3 31-a2 31-a1 31-a0
pand mm5,mm7; //g7: mm5=dg3 dg2 dg1 dg0
movq mm3,[esi]; //b1: mm3=src3 src2 src1 src0
pmullw mm4,mm1; //g8: mm4=sg?*a?
movq mm7,MASKR; //b2: mm7=blue mask
pmullw mm5,mm2; //g9: mm5=dg?*(1-a?)
movq mm0,[edi]; //b3: mm0=dst3 dst2 dst1 dst0
pand mm3,mm7; //b4: mm3=sb3 sb2 sb1 sb0
pand mm0,mm7; //b5: mm0=db3 db2 db1 db0
pmullw mm3,mm1; //b6: mm3=sb?*a?
movq mm7,[esi]; //r1: mm7=src3 src2 src1 src0
paddw mm4,mm5; //g10: mm4=sg?*a?+dg?*(1-a?)
paddw mm4,FIVETWELVE; //g11: mm4=(mm4+512) green
pmullw mm0,mm2; //b7: mm0=db?*(1-a?)
pand mm7,MASKB; //r2: mm7=sr3 sr2 sr1 sr0
movq mm5,mm4; //g12: mm5=mm4 green
psrlw mm4,5; //g13: mm4=mm4>>5
paddw mm4,mm5; //g14: mm4=mm5+mm4 green
movq mm5,[edi]; //r3: mm5=dst3 dst2 dst1 dst0
paddw mm0,mm3; //b8: mm0=sb?*a?+db?*(1-a?)
paddw mm0,SIXTEEN; //b9: mm0=(mm0+16) blue
psrlw mm7,10; //r4: shift src red down to position 0
pand mm5,MASKB; //r5: mm5=dr3 dr2 dr1 dr0
psrlw mm4,5; //g15: mm4=0?g0 0?g0 0?g0 0?g0 green
movq mm3,mm0; //b10: mm3=mm0 blue
psrlw mm0,5; //b11: mm0=mm0>>5 blue
psrlw mm5,10; //r6: shift dst red down to position 0
paddw mm0,mm3; //b12: mm0=mm3+mm0 blue
psrlw mm0,5; //b13: mm0=000b 000b 000b 000b blue
pmullw mm7,mm1; //mm7=sr?*a?
pand mm4,MASKG; //g16: mm4=00g0 00g0 00g0 00g0 green
pmullw mm5,mm2; //r7: mm5=dr?*(31-a?)
por mm0,mm4; //mm0=00gb 00gb 00gb 00gb
add eax,4; //move to next 4 alphas
add esi,8; //move to next 4 pixels in src
add edi,8; //move to next 4 pixels in dst
movd mm1,[eax]; //mm1=00 00 00 00 a3 a2 a1 a0
paddw mm5,mm7; //r8: mm5=sr?*a?+dr?*(31-a?)
paddw mm5,SIXTEEN; //r9: mm5=(mm5+16) red
pxor mm2,mm2; //mm0=0;
movq mm7,mm5; //r10: mm7=mm5 red
psrlw mm5,5; //r11: mm5=mm5>>5 red
movq mm4,[esi]; //g1: mm4=src3 src2 src1 src0
paddw mm5,mm7; //r12: mm5=mm7+mm5 red
punpcklbw mm1,mm2; //mm1=00a3 00a2 00a1 00a0
psrlw mm5,5; //r13: mm5=mm5>>5 red
psllw mm5,10; //r14: mm5=mm5<<10 red
por mm0,mm5; //mm0=0rgb 0rgb 0rgb 0rgb
sub ebx,4; //polished off 4 pixels
movq [edi-8],mm0; //dst=0rgb 0rgb 0rgb 0rgb
jmp loopqword; //go back to start
copyback:
movq [edi],mm4; //copy source to destination
leavefront:
add edi,8; //advance destination by 4 pixels
add eax,4; //advance alpha by 4
add esi,8; //advance source by 4 pixels
sub ebx,4; //decrease pixel count by 4
jmp primeloop;
checkback:
test ebx,0xFF; //check if 0 pixels left
jz nextline; //done with this span
//backalign: //work out back end pixels
movq mm5,[edi]; //g2: mm5=dst3 dst2 dst1 dst0
psrlw mm1,3; //mm1=a?>>3 nuke out lower 3 bits
movq mm7,MASKG; //g3: mm7=green mask
movq mm0,mm1; //mm0=00a3 00a2 00a1 00a0
movq mm2,MASKR; //g4: mm2=31 mask
pand mm4,mm7; //g5: mm4=sg3 sg2 sg1 sg0
psubsb mm2,mm0; //g6: mm2=31-a3 31-a2 31-a1 31-a0
pand mm5,mm7; //g7: mm5=dg3 dg2 dg1 dg0
movq mm3,[esi]; //b1: mm3=src3 src2 src1 src0
pmullw mm4,mm1; //g8: mm4=sg?*a?
movq mm7,MASKR; //b2: mm7=blue mask
pmullw mm5,mm2; //g9: mm5=dg?*(1-a?)
movq mm0,[edi]; //b3: mm0=dst3 dst2 dst1 dst0
pand mm3,mm7; //b4: mm3=sb3 sb2 sb1 sb0
pand mm0,mm7; //b5: mm0=db3 db2 db1 db0
pmullw mm3,mm1; //b6: mm3=sb?*a?
movq mm7,[esi]; //r1: mm7=src3 src2 src1 src0
paddw mm4,mm5; //g10: mm4=sg?*a?+dg?*(1-a?)
paddw mm4,FIVETWELVE; //g11: mm4=(mm4+512) green
pmullw mm0,mm2; //b7: mm0=db?*(1-a?)
pand mm7,MASKB; //r2: mm7=sr3 sr2 sr1 sr0
movq mm5,mm4; //g12: mm5=mm4 green
psrlw mm4,5; //g13: mm4=mm4>>5
paddw mm4,mm5; //g14: mm4=mm4+mm5 green
movq mm5,[edi]; //r3: mm5=dst3 dst2 dst1 dst0
paddw mm0,mm3; //b8: mm0=sb?*a?+db?*(1-a?)
paddw mm0,SIXTEEN; //b9: mm0=mm0 blue
psrlw mm7,10; //r4: shift src red down to position 0
pand mm5,MASKB; //r5: mm5=dr3 dr2 dr1 dr0
psrlw mm4,5; //g15: mm4=0?g0 0?g0 0?g0 0?g0 green
movq mm3,mm0; //b10: mm3=mm0 blue
psrlw mm0,5; //b11: mm0=mm0>>5 blue
psrlw mm5,10; //r6: shift dst red down to position 0
paddw mm0,mm3; //b12: mm0=mm0+mm3 blue
psrlw mm0,5; //b13: mm0=000b 000b 000b 000b blue
pmullw mm7,mm1; //mm7=sr?*a?
pand mm4,MASKG; //g16: mm4=00g0 00g0 00g0 00g0 green
pmullw mm5,mm2; //r7: mm5=dr?*(31-a?)
por mm0,mm4; //mm0=00gb 00gb 00gb 00gb
//stall
paddw mm5,mm7; //r8: mm5=sr?*a?+dr?*(31-a?)
paddw mm5,SIXTEEN; //r9: mm5=mm5 red
movq mm7,mm5; //r10: mm7=mm5 red
psrlw mm5,5; //r11: mm5=mm5>>5 red
paddw mm5,mm7; //r12: mm5=mm5+mm7 red
psrlw mm5,5; //r13: mm5=mm5>>5 red
psllw mm5,10; //r14: mm5=mm5<<10 red
por mm0,mm5; //mm0=0rgb 0rgb 0rgb 0rgb
test ebx,2; //check if there are 2 pixels
jz oneendpixel; //goto one pixel if that's it
movd [edi],mm0; //dst=0000 0000 0rgb 0rgb
psrlq mm0,32; //mm0>>32
add edi,4; //edi=edi+4
sub ebx,2; //saved 2 pixels
jz nextline; //all done goto next line
oneendpixel: //work on last pixel
movd edx,mm0; //edx=0rgb
mov [edi],dx; //dst=0rgb
nextline: //goto next line
dec ecx; //nuke one line
jz done; //all done
mov eax,lpLinearAlpBp; //alpha
mov esi,lpLinearSrcBp; //src
mov edi,lpLinearDstBp; //dst
add eax,iAlpPitch; //inc alpha ptr by 1 line
add esi,iSrcPitch; //inc src ptr by 1 line
add edi,iDstPitch; //inc dst ptr by 1 line
mov lpLinearAlpBp,eax; //save new alpha base ptr
mov ebx,iDstW; //ebx=span width to copy
mov lpLinearSrcBp,esi; //save new src base ptr
mov lpLinearDstBp,edi; //save new dst base ptr
jmp primeloop; //start the next span
done:
emms
}
}
/*Alpha blending routine for 565 video hardware
lpAlpha=Pointer to location of 8-bit alpha mask
iAlpPitch=The span of a row in the alpha mask
lpSrc=Pointer to location of 16-bit 565 source bitmap
iSrcX=Starting X location of 16-bit source bitmap
iSrcY=Starting Y location of 16-bit source bitmap
iSrcPitch=The span of a row of pixels in the Source bitmap
lpDst=Pointer to location of 16-bit 565 destination bitmap
iDstX=Starting X location of 16-bit destination bitmap
iDstY=Starting Y location of 16-bit destination bitmap
iDstW=Width in pixels for alpha mask, source and destination bitmaps
iDstH=Height in pixels for alpha mask, source and destination bitmaps
iDstPitch=The span of a row of pixels in the destination bitmap*/
void ablend_565(unsigned char *lpAlpha,unsigned int iAlpPitch,
unsigned char *lpSrc,unsigned int iSrcX, unsigned int iSrcY,
unsigned int iSrcPitch, unsigned char *lpDst,
unsigned int iDstX, unsigned int iDstY,
unsigned int iDstW, unsigned int iDstH,
unsigned int iDstPitch)
{
//Mask for isolating the red,green, and blue components
static __int64 MASKB=0x001F001F001F001F;
static __int64 MASKG=0x07E007E007E007E0;
static __int64 MASKSHIFTG=0x03F003F003F003F0;
static __int64 MASKR=0xF800F800F800F800;
//constants used by the integer alpha blending equation
static __int64 SIXTEEN=0x0010001000100010;
static __int64 FIVETWELVE=0x0200020002000200;
static __int64 SIXONES=0x003F003F003F003F;
unsigned char *lpLinearDstBp=(iDstX<<1)+(iDstY*iDstPitch)+lpDst; //base pointer for linear destination
unsigned char *lpLinearSrcBp=(iSrcX<<1)+(iSrcY*iSrcPitch)+lpSrc; //base pointer for linear source
unsigned char *lpLinearAlpBp=iSrcX+(iSrcY*iAlpPitch)+lpAlpha; //base pointer for linear alpha
_asm{
mov esi,lpLinearSrcBp; //src
mov edi,lpLinearDstBp; //dst
mov eax,lpLinearAlpBp; //alpha
mov ecx,iDstH; //ecx=number of lines to copy
mov ebx,iDstW; //ebx=span width to copy
test esi,6; //check if source address is qword aligned
//since addr coming in is always word aligned(16bit)
jnz done; //if not qword aligned we don't do anything
primeloop:
movd mm1,[eax]; //mm1=00 00 00 00 a3 a2 a1 a0
pxor mm2,mm2; //mm2=0;
movq mm4,[esi]; //g1: mm4=src3 src2 src1 src0
punpcklbw mm1,mm2; //mm1=00a3 00a2 00a1 00a0
loopqword:
mov edx,[eax];
test ebx,0xFFFFFFFC; //check if only 3 pixels left
jz checkback; //3 or less pixels left
//early out tests
cmp edx,0xffffffff; //test for alpha value of 1
je copyback; //if 1's copy the source pixels to the destination
test edx,0xffffffff; //test for alpha value of 0
jz leavefront; //if so go to the next 4 pixels
//the alpha blend starts
//green
//i=a*sg+(63-a)*dg;
//i=(i+32)+((i+32)>>6)>>6;
//red
//i=a*sr+(31-a)*dr;
//i=(i+16)+((i+16)>>5)>>5;
movq mm5,[edi]; //g2: mm5=dst3 dst2 dst1 dst0
psrlw mm1,2; //mm1=a?>>2 nuke out lower 2 bits
movq mm7,MASKSHIFTG; //g3: mm7=1 bit shifted green mask
psrlw mm4,1; //g3a: move src green down by 1 so that we won't overflow
movq mm0,mm1; //mm0=00a3 00a2 00a1 00a0
psrlw mm5,1; //g3b: move dst green down by 1 so that we won't overflow
psrlw mm1,1; //mm1=a?>>1 nuke out lower 1 bits
pand mm4,mm7; //g5: mm4=sg3 sg2 sg1 sg0
movq mm2,SIXONES;//g4: mm2=63
pand mm5,mm7; //g7: mm5=dg3 dg2 dg1 dg0
movq mm3,[esi]; //b1: mm3=src3 src2 src1 src0
psubsb mm2,mm0; //g6: mm2=63-a3 63-a2 63-a1 63-a0
movq mm7,MASKB; //b2: mm7=BLUE MASK
pmullw mm4,mm0; //g8: mm4=sg?*a?
movq mm0,[edi]; //b3: mm0=dst3 dst2 dst1 dst0
pmullw mm5,mm2; //g9: mm5=dg?*(1-a?)
movq mm2,mm7; //b4: mm2=fiveones
pand mm3,mm7; //b4: mm3=sb3 sb2 sb1 sb0
pmullw mm3,mm1; //b6: mm3=sb?*a?
pand mm0,mm7; //b5: mm0=db3 db2 db1 db0
movq mm7,[esi]; //r1: mm7=src3 src2 src1 src0
paddw mm4,mm5; //g10: mm4=sg?*a?+dg?*(1-a?)
pand mm7,MASKR; //r2: mm7=sr3 sr2 sr1 sr0
psubsb mm2,mm1; //b5a: mm2=31-a3 31-a2 31-a1 31-a0
paddw mm4,FIVETWELVE; //g11: mm4=(mm4+512) green
pmullw mm0,mm2; //b7: mm0=db?*(1-a?)
movq mm5,mm4; //g12: mm5=mm4 green
psrlw mm7,11; //r4: shift src red down to position 0
psrlw mm4,6; //g13: mm4=mm4>>6
paddw mm4,mm5; //g14: mm4=mm4+mm5 green
paddw mm0,mm3; //b8: mm0=sb?*a?+db?*(1-a?)
movq mm5,[edi]; //r3: mm5=dst3 dst2 dst1 dst0
paddw mm0,SIXTEEN; //b9: mm0=(mm0+16) blue
pand mm5,MASKR; //r5: mm5=dr3 dr2 dr1 dr0
psrlw mm4,5; //g15: mm4=0?g0 0?g0 0?g0 0?g0 green
movq mm3,mm0; //b10: mm3=mm0 blue
psrlw mm0,5; //b11: mm0=mm0>>5 blue
psrlw mm5,11; //r6: shift dst red down to position 0
paddw mm0,mm3; //b12: mm0=mm3+mm0 blue
psrlw mm0,5; //b13: mm0=000b 000b 000b 000b blue
pmullw mm7,mm1; //mm7=sr?*a?
pand mm4,MASKG; //g16: mm4=00g0 00g0 00g0 00g0 green
pmullw mm5,mm2; //r7: mm5=dr?*(31-a?)
por mm0,mm4; //mm0=00gb 00gb 00gb 00gb
add eax,4; //move to next 4 alphas
add esi,8; //move to next 4 pixels in src
add edi,8; //move to next 4 pixels in dst
movd mm1,[eax]; //mm1=00 00 00 00 a3 a2 a1 a0
paddw mm5,mm7; //r8: mm5=sr?*a?+dr?*(31-a?)
paddw mm5,SIXTEEN; //r9: mm5=(mm5+16) red
pxor mm2,mm2; //mm2=0;
movq mm7,mm5; //r10: mm7=mm5 red
psrlw mm5,5; //r11: mm5=mm5>>5 red
movq mm4,[esi]; //g1: mm4=src3 src2 src1 src0
paddw mm5,mm7; //r12: mm5=mm7+mm5 red
punpcklbw mm1,mm2; //mm1=00a3 00a2 00a1 00a0
psrlw mm5,5; //r13: mm5=mm5>>5 red
psllw mm5,11; //r14: mm5=mm5<<10 red
por mm0,mm5; //mm0=0rgb 0rgb 0rgb 0rgb
sub ebx,4; //polished off 4 pixels
movq [edi-8],mm0; //dst=0rgb 0rgb 0rgb 0rgb
jmp loopqword; //go back to start
copyback:
movq [edi],mm4; //copy source to destination
leavefront:
add edi,8; //advance destination by 4 pixels
add eax,4; //advance alpha by 4
add esi,8; //advance source by 4 pixels
sub ebx,4; //decrease pixel count by 4
jmp primeloop;
checkback:
test ebx,0xFF; //check if 0 pixels left
jz nextline; //done with this span
//backalign: //work out back end pixels
movq mm5,[edi]; //g2: mm5=dst3 dst2 dst1 dst0
psrlw mm1,2; //mm1=a?>>2 nuke out lower 2 bits
movq mm7,MASKSHIFTG; //g3: mm7=shift 1 bit green mask
psrlw mm4,1; //g3a: move src green down by 1 so that we won't overflow
movq mm0,mm1; //mm0=00a3 00a2 00a1 00a0
psrlw mm5,1; //g3b: move dst green down by 1 so that we won't overflow
psrlw mm1,1; //mm1=a?>>1 nuke out lower 1 bits
pand mm4,mm7; //g5: mm4=sg3 sg2 sg1 sg0
movq mm2,SIXONES;//g4: mm2=63
pand mm5,mm7; //g7: mm5=dg3 dg2 dg1 dg0
movq mm3,[esi]; //b1: mm3=src3 src2 src1 src0
psubsb mm2,mm0; //g6: mm2=63-a3 63-a2 63-a1 63-a0
movq mm7,MASKB; //b2: mm7=BLUE MASK
pmullw mm4,mm0; //g8: mm4=sg?*a?
movq mm0,[edi]; //b3: mm0=dst3 dst2 dst1 dst0
pmullw mm5,mm2; //g9: mm5=dg?*(1-a?)
movq mm2,mm7; //b4: mm2=fiveones
pand mm3,mm7; //b4: mm3=sr3 sr2 sr1 sr0
pmullw mm3,mm1; //b6: mm3=sb?*a?
pand mm0,mm7; //b5: mm0=db3 db2 db1 db0
movq mm7,[esi]; //r1: mm7=src3 src2 src1 src0
paddw mm4,mm5; //g10: mm4=sg?*a?+dg?*(1-a?)
pand mm7,MASKR; //r2: mm7=sr3 sr2 sr1 sr0
psubsb mm2,mm1; //b5a: mm2=31-a3 31-a2 31-a1 31-a0
paddw mm4,FIVETWELVE; //g11: mm4=(i+512) green
pmullw mm0,mm2; //b7: mm0=db?*(1-a?)
movq mm5,mm4; //g12: mm5=(i+512) green
psrlw mm7,11; //r4: shift src red down to position 0
psrlw mm4,6; //g13: mm4=(i+512)>>6
paddw mm4,mm5; //g14: mm4=(i+512)+((i+512)>>6) green
paddw mm0,mm3; //b8: mm0=sb?*a?+db?*(1-a?)
movq mm5,[edi]; //r3: mm5=dst3 dst2 dst1 dst0
paddw mm0,SIXTEEN; //b9: mm0=(i+16) blue
pand mm5,MASKR; //r5: mm5=dr3 dr2 dr1 dr0
psrlw mm4,5; //g15: mm4=0?g0 0?g0 0?g0 0?g0 green
movq mm3,mm0; //b10: mm3=(i+16) blue
psrlw mm0,5; //b11: mm0=(i+16)>>5 blue
psrlw mm5,11; //r6: shift dst red down to position 0
paddw mm0,mm3; //b12: mm0=(i+16)+(i+16)>>5 blue
psrlw mm0,5; //b13: mm0=000r 000r 000r 000r blue
pmullw mm7,mm1; //mm7=sr?*a?
pand mm4,MASKG; //g16: mm4=00g0 00g0 00g0 00g0 green
pmullw mm5,mm2; //r7: mm5=dr?*(31-a?)
por mm0,mm4; //mm0=00gb 00gb 00gb 00gb
add eax,4; //move to next 4 alphas
//stall
paddw mm5,mm7; //r8: mm5=sr?*a?+dr?*(31-a?)
paddw mm5,SIXTEEN; //r9: mm5=(i+16) red
movq mm7,mm5; //r10: mm7=(i+16) red
psrlw mm5,5; //r11: mm5=(i+16)>>5 red
paddw mm5,mm7; //r12: mm5=(i+16)+((i+16)>>5) red
psrlw mm5,5; //r13: mm5=(i+16)+((i+16)>>5)>>5 red
psllw mm5,11; //r14: mm5=mm5<<10 red
por mm0,mm5; //mm0=0rgb 0rgb 0rgb 0rgb
test ebx,2; //check if there are 2 pixels
jz oneendpixel; //goto one pixel if that's it
movd [edi],mm0; //dst=0000 0000 0rgb 0rgb
psrlq mm0,32; //mm0>>32
add edi,4; //edi=edi+4
sub ebx,2; //saved 2 pixels
jz nextline; //all done goto next line
oneendpixel: //work on last pixel
movd edx,mm0; //edx=0rgb
mov [edi],dx; //dst=0rgb
nextline: //goto next line
dec ecx; //nuke one line
jz done; //all done
mov eax,lpLinearAlpBp; //alpha
mov esi,lpLinearSrcBp; //src
mov edi,lpLinearDstBp; //dst
add eax,iAlpPitch; //inc alpha ptr by 1 line
add esi,iSrcPitch; //inc src ptr by 1 line
add edi,iDstPitch; //inc dst ptr by 1 line
mov lpLinearAlpBp,eax; //save new alpha base ptr
mov ebx,iDstW; //ebx=span width to copy
mov lpLinearSrcBp,esi; //save new src base ptr
mov lpLinearDstBp,edi; //save new dst base ptr
jmp primeloop; //start the next span
done:
emms
}
}
